Fair and Fast k-Center Clustering

Project Objectives:
This project is about a highly efficient k-center algorithm, which is a central piece of our publication at the International Conference on Machine Learning (ICML). The algorithm addresses two key issues faced by many clustering methods when used for data summarization:
Unfair representation of “demographic groups”.
Distorted summarizations, where data points in the summary represent subsets of the original data of vastly different sizes.
Our k-center algorithm effectively addresses both issues simultaneously. It is fast, both in theory and practice, with a linear-running time in the number of points, exhibits a worst-case constant-factor guarantee, and gives promising computational results showing that there can be significant benefits in addressing both issues together instead of sequentially.
For more details, please refer to our ICML paper.
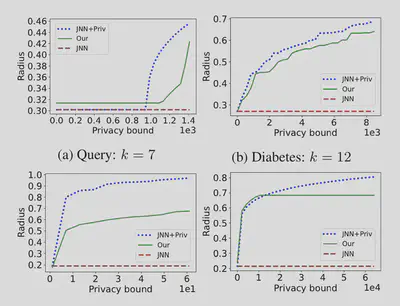
Technological Stack:
The algorithm is developed in Rust, utilizing very fast parallel computing. It incorporates matching algorithms, basic k-center algorithms, flow computations, and other graph procedures. Additionally, we provide Python bindings for ease of integration with Python-based projects.
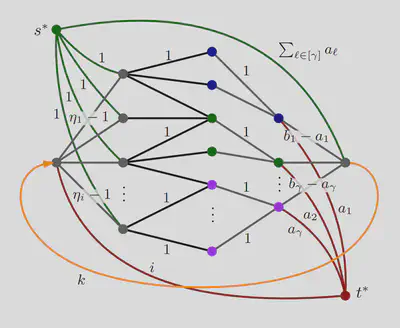
My Role
The very high-level idea of the algorithm was a team-effort, however, the implementation and the specification of the details (and there are a lot of details) was my job. The main challenge was to keep the promised running time of $O(nk^2 + k^5)$ which required a lot of extra tweaks, which are listed in the appendix of the paper.